[컴퓨터 구조] 컴퓨터 구조와 운영체제.
간단히 알아보는 컴퓨터 구조와 운영체제
해당 포스팅은 혼자 공부하는 컴퓨터구조+운영체제를 기반으로 작성하는 글입니다.
총 15개의 챕터로 이루어져 있으며 3개의 챕터를 나눠서 포스팅하겠습니다.
✔️먼저읽기✔️
Chapter 1.
컴퓨터 구조의 필요성과 핵심 부품들을 살펴봅시다.
Chapter 2.
데이터의 정보 단위, 2진법과 16진법, 인코딩에 대해 알아봅시다.
Chapter 3.
명령어의 구조와 고급 언어/저급 언어에 대해 알아봅시다.
참고자료
강민철. 『혼자 공부하는 컴퓨터구조 + 운영체제』, 한빛미디어(2022년 출간)
Chapter 1
개발자의 기초 역량 컴퓨터의 구조.
컴퓨터 구조는 컴퓨터가 어떻게 동작하는지를 들여다 보는 것 입니다.
개발자가 프로그램을 만들 때는 성능/비용/용량 등을 고려하고
오류가 발생했을 때 문제의 원인을 해결하는데 도움이 됩니다.
컴퓨터의 핵심부품.
컴퓨터의 주요 부품은 4가지로 분류했습니다.
중앙처리장치는 두뇌의 역활을 담당합니다.
[부품 중 CPU에 해당]
주기억장치는 컴퓨터 실행 시 실시간 정보를 담는 장치입니다.
[부품 중 RAM에 해당]
보조기억장치는 저장 공간을 담당합니다.
[부품 중 SSD/HDD에 해당]
입출력장치는 사용자와의 상호작용을 담당합니다.
[부품 중 모니터와 마우스, 키보드, 스피커 등에 해당]

CPU
CPU는 주요 구성 요소 3개로 ALU, 제어장치, 레지스터가 있습니다.
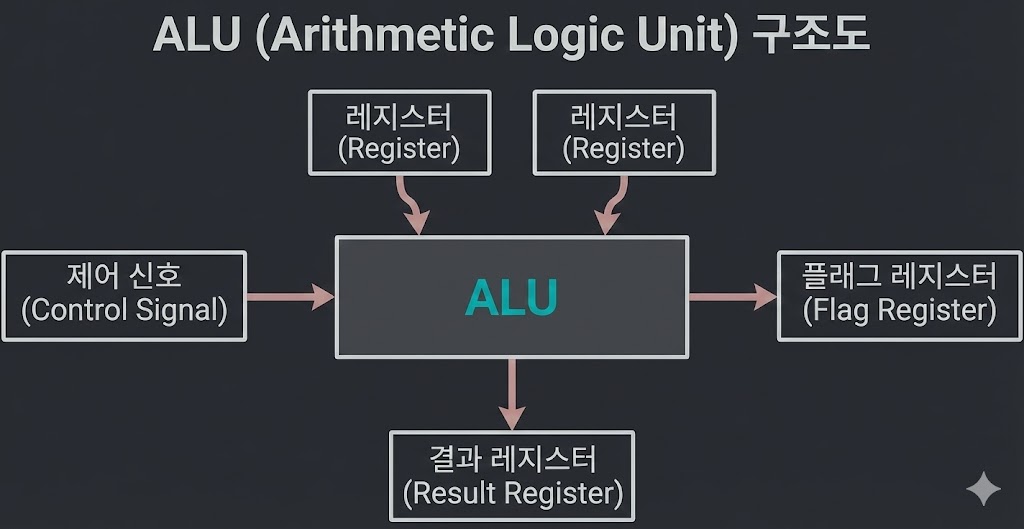
Arithmetic Logic Unit(산술논리연산장치)
- ALU는 CPU 내부의 계산(연산)을 담당합니다.
- 레지스터로부터 피연산자를 받아 연산을 수행합니다.
- 연산 결과 부가 정보는 플래그 레지스터(부호, 제로, 오버플로우 등)를 통해 표현합니다.
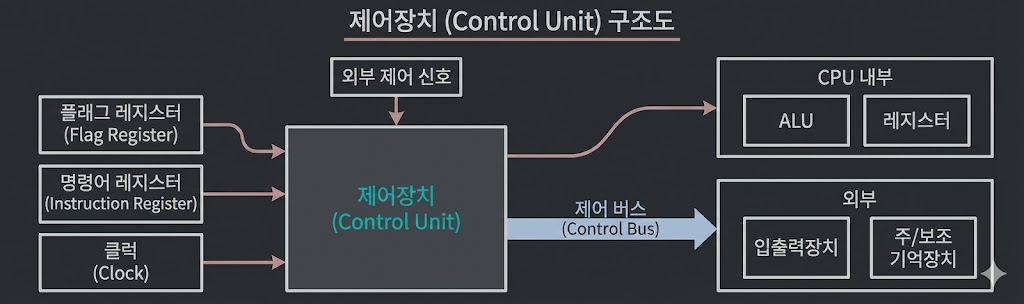
Control Unit(제어장치)
-
제어신호를 내보내거나 명령어를 해석하는 장치입니다.
[대표적인 제어신호로 메모리 읽기/쓰기가 있습니다.] -
클럭 단위로 동작하며 신호를 발생시킵니다.
[명령어와 플래그 레지스터의 정보를 받아 해석 후 제어 신호를 생성] -
생성된 신호는 ALU와 레지스터(CPU 내부)로 전달됩니다.
혹은 메모리와 입출력장치(CPU 외부)로 전달되기도 합니다.
Register(레지스터)
-
CPU 내부의 임시 저장 장치이며 주요 레지스터는 4가지입니다.
-
프로그램 카운터(PC)는 실행할 명령어의 위치(주소)를 저장합니다.
[다른 말로 명령어 포인터이며 명령이 실행되면 값(주소)을 증가시킴] -
명령어 레지스터(IR)는 해석할 명령어를 저장합니다.
[제어장치는 이를 받아들이고 제어 신호로 변환하여 내보냄] -
메모리 주소 레지스터(MAR)는 읽고 싶은 주소 값을 담습니다.
[CPU가 메모리에 접근할 때 주소 버스를 이용] -
메모리 버퍼 레지스터(MBR)는 주고받을 데이터와 명령어를 저장합니다.
[다른 말로 메모리 데이터 레지스터이며 데이터 버스를 이용]
메모리
메모리는 명령어와 데이터의 저장공간입니다.
메모리에 접근하기 위해 주소를 사용합니다.
특징 1, 메모리는 전원이 차단되면 모든 정보가 사라지는 휘발성 성질을 갖고 있습니다.
특징 2, 메모리는 실행 정보를 관리하므로 읽고 쓰는 속도가 빠르지만 비용이 비쌉니다.
[이는 실행 프로그램의 정보는 메모리가 갖는게 적합하다는 의미]
1. 네비게이션의 경유지 또는 도착지라 할 수 있습니다.
2. 도착지나 경유지를 찾아가려면 주소를 먼저 입력합니다.
3. 메모리의 데이터(도착지)에 새로운 주소가 저장되어 있을 수 있습니다. 이는 마치 경유지와 같죠!
<대략적인 흐름>
[첫번째 명령어: 10번지와 12번지를 더해라]
- 제어장치(읽기 신호) -
메모리에서 얻어온 명령어를 레지스터에 저장. - 제어장치(해석) -
가져온 명령어를 해석. - 제어장치(읽기 신호) -
메모리(10번지, 12번지) 데이터 확보 후, 각각 레지스터에 저장. - ALU(연산) -
결과 값을 레지스터에 저장.
[두번째 명령어: 20번지에 저장해라]
- 제어장치(읽기 신호) -
메모리에서 얻어온 명령어를 레지스터에 저장. - 제어장치(해석) -
가져온 명령어를 해석. - 제어장치(쓰기 신호) -
레지스터에 저장된 결과 값을 연산된 메모리(20번지)에 갱신.
보조기억장치
앞선 메모리의 특징들의 약점을 보안하기 위한 장치입니다.
주로 설치된 프로그램의 정보를 저장합니다.
보조기억장치로는 하드 디스크, SSD, USB 메모리, DVD, CD-ROM 등 있습니다.
특징 1 보조기억장치는 저장공간이 크고 비휘발성 성질을 가집니다.
[즉, 전원이 꺼져도 프로그램 정보를 보관]
특징 2 보조기억장치는 읽고 쓰기 성능이 메모리에 비해 부족, 비용은 상대적으로 저렴합니다.
입출력장치
마이크, 스피커, 프린터, 마우스, 키보드와 같이 컴퓨터 외부에서 신호를 주고받는 장치입니다.
그렇기 때문에 이를 합쳐 주변장치로 통칭하기도 합니다.
메인보드와 시스템 버스
메인보드는 여러 컴퓨터 부품을 연결하는 슬롯과 단자가 있습니다.
메인보드 내부의 버스라는 통로를 통해 연결 부품들은 정보를 전송합니다.
이는 시스템 버스라 부르고 제어버스/주소버스/데이터버스로 구분합니다.
제어버스는 읽기/쓰기와 같은 제어 신호를 보낼 때
주소버스는 주소를 주고 받을 때
데이터버스는 데이터와 명령어를 주고 받을 때
1. 데이터를 보낸다. (데이터버스)
2. 읽을지 쓸지 결정한다. (제어버스)
3. 어디에 저장할지 결정한다. (주소버스)
각각의 정보를 전용 통로를 통해 보냅니다.
Chapter 2
데이터의 숫자 표현
컴퓨터의 모든 데이터는 0, 1로 표현합니다.
[즉, 전기신호의 불이 On/Off 인지를 나타냄]
정보의 단위
비트는 0과 1을 표현하는 기본 단위(전구 1개)
바이트는 비트 8개를 묶은 단위(전구 8개)
[모든 전구 상태의 표현 가짓수는 28 = 256]
| 1byte | 8bit |
| 1KB | 1000byte |
| 1MB | 1000KB |
| 1GB | 1000MB |
워드는 CPU가 한 번의 처리할 수 있는 데이터양입니다.
[워드당 16비트, 32비트, 64비트 등]
2진법
2진법은 컴퓨터의 숫자 표현 방식입니다.(0, 1)
10진법은 1~9를 사용하는 인간의 숫자 표현 방식입니다.
즉, n진법은 n개의 숫자를 갖는 숫자 표현 방식이겠죠?
2의 보수
2의 보수는 2진법의 음수 표현 방식입니다.

간단 계산법은 위와 같지만 수식으로 풀자면 다음과 같습니다.
[2의 보수는 표현 가능 값 보다 큰 2n 값을 뺀 결과 값.]
4bit로 표현 가능한 범위 0~15
표현 가능 값 15보다 큰 2n 값은 16결과 값: 16 - 5(01012) = 11(10112)
그렇다면 어떻게 음수인지 구별하죠?
보통 가장 앞 비트를 부호 플래그로 봅니다. 0 - 양수, 1 - 음수
그렇다면 왜 2의 보수를 써야할까요?
2의 보수 방식을 사용하면 음수 값을 [합 연산 / 2의 보수 전환]만으로 연산할 수 있습니다.
달리 말하면 +연산으로 -를 처리할 수 있는 이점이 큽니다.
부호 비트까지 확장하면 3(000112), -5(110112) 결과는 14(111102).
이를 2의 보수를 취하면 2가 나옵니다.
즉, 111102은 -2인 것이죠!
16진법
2진법은 너무 적은 정보를 담고 있습니다.
4byte: 01011001 00011010 11010011 10111111
난잡한 바코드같지 않나요?
16이란 수는 24, 총 4개의 bit를 표현 가능합니다.
이를 숫자와 알파벳을 결합해 16를 표현한다면?
0 ~ 9, A(10), B(11), C(12), D(13), E(14), F(15). 총 16개
바코드 같던 수를 16진법으로 다시 표현하면?
4byte": 59 1A D3 BF
데이터의 문자 표현
인간 문화 언어(영어/한국어 등)들은 인코딩/디코딩 과정으로 컴퓨터 언어와 변환합니다.
인코딩과 디코딩
이는 컴퓨터의 표현 숫자와 인간의 문자 집합을 단순히 대응한 것에 대한 이야기입니다.
대표적으로 아스키 코드, 유니코드가 있습니다.
아스키코드
해당 표준은 7비트, 즉 128개의 문자(알파벳, 숫자, 특문) 표현 가능합니다.
[1bit는 패리티 비트(오류 검출용)로 사용]

EUC-KR
물론 한글 인코딩도 있습니다.
이는 한 글자를 2byte(16비트)로 표현합니다.
인코딩 방식은 완성형과 조합형 두 가지 존재합니다.
완성형 글자 하나를 통째로 매핑하는 방식입니다.
조합형 초성, 중성, 종성에 비트열을 할당합니다.
[정렬과 검색 작업에 취약하여 현재는 거의 사용되지 않음]
이후 CP949로 확장됐지만, 유니코드의 등장으로 대부분 넘어갔습니다.
유니코드
다른 언어 인코딩을 지원하지 않은 경우 글자가 깨지거나 볼 수 없게 됩니다.
유니코드는 전 세계 모든 문자를 하나로 통합하여 해결합니다.
UTF-8
UTF의 약자는 Unicode Transformation Format입니다.
즉, 유니코드 정보를 담는 방식입니다.
숫자는 인코딩 단위(8bit, 16bit, 32bit)를 뜻합니다.
UTF-8 1~4byte(가변)
[영어는 1byte, 한글은 3byte]
UTF-16 2, 4바이트(가변)
[Java 초기 설계에 UTF-16을 채택]
UTF-32 4byte(고정)
[단순하지만 저장 효율이 떨어짐]
대부분 1byte 체계(아스키코드, 마크다운 등)와도 호환 가능하고 가변에 능한 UTF-8을 사용합니다.
Chapter 3
소스 코드와 명령어
여태까지 컴퓨터와 인간의 표현 방식을 배웠습니다.
하지만 컴퓨터는 어떻게 동작할까요?
우리는 명령을 실행하기 위해 인간의 문법인 프로그래밍 언어를 사용합니다.
[대표적인 C, C++, Python, Java]
이를 컴퓨터가 어떻게 이해하죠?
인간의 명령과 0과 1의 관계를 어떻게 정의하죠?
기계어
컴퓨터의 설계는 0과 1의 정보만으로 설계됐습니다.
하지만 0과 1로 무엇을 할 수 있는 지는 모르죠.
이를 정의한 것이 기계어입니다.
고급언어와 저급언어
저급언어는 0과 1로 구성된 기계어를 인간의 언어로 번역한 것입니다.
고급언어는 저급언어의 명령들을 모듈화한 것입니다.
고급언어 프로그래밍 언어(C, C+, Python, Java 등)
<stdio.h>
int main()
{
printf("Hello world");
return 0;
}
[C언어 - printf함수 안에는 수많은 어셈블리 코드가 작동]
저급언어 기계어, 어셈블리어
push rbp
mov rbp, rsp
pop rbp
[어셈블리어 - push rbp는 기계어 0101 0101 해당]
컴퓨터의 핵심 역활은 데이터의 읽기, 쓰기, 연산입니다.
사용자는 데이터의 선정방식, 연산 방식 등 수많은 방법을 제시하죠.
저급언어는 컴퓨터에 가장 근접한 번역어이지만
가독성이, 편리한 문법 등 대다수 개발자들은 프로그래밍 언어를 사용합니다.
컴파일 언어와 인터프리터 언어
프로그래밍 언어는 저급언어로 변환이 되어야 컴퓨터가 수행가능합니다.
이 과정에서 고급언어에서 저급언어로 변환하는 방식입니다.
컴파일 언어는 소스코드를 기계어로 변환합니다.
컴파일 완료 시 소스코드는 컴퓨터가 이해 가능한 목적코드로 변환합니다.
컴파일 수행 도구인 컴파일러는 최적화, 문법 검사, 기계어로 변환 등을 수행합니다.
[하나라도 오류나면 컴파일 실패]
인터프리터 언어는 소스코드가 한 줄씩 실행됩니다.
오류가 있어도 오류 직전까지 실행됩니다.
컴파일 언어 / 인터프리터 언어 차이점
| 컴파일 언어 | 인터프리터 언어 | |
|---|---|---|
| 번역시점 | 실행 전 | 실행 시 |
| 목적파일 | 생성 | 미생성 |
| 장점 | 실행속도가 빠름 | 코드 수정 후 즉시 확인 |
| 대표언어 | C, C++ | Python |
컴파일 언어 특징
실행 시 컴파일 언어가 기계어로 변환하는 과정을 넘겨 속도가 빠름니다.
하지만 파일이 클 수록 빌드 시간도 상당히 오래 걸립니다.
즉, 실행속도나 성능을 중점으로 둔 게임, VFX 등은 C, C++, C#을 주로 사용합니다.
인터프리터 언어 특징
코드 수정으로 즉각적인 결과를 본다면 작업속도 효율이 높아집니다.
즉, 작업속도를 중점으로 둔 데이터 분석, 웹 서버, 자동화 툴 등은 Python을 주로 사용합니다.
python도 컴파일을 합니다. [대표적으로 .pyc파일]
목적파일과 실행파일
목적파일에서 링킹과정을 거치면 실행파일이 됩니다.
[윈도우의 .exe확장자가 대표적인 실행파일]
여러 개로 나뉜 목적파일들을 하나로 연결하는 과정을 링킹이라고 합니다.
명령어의 구조
우리가 작성한 명령어의 구조는 어떨까요?
연산 코드와 오퍼랜드
명령어는 연산자인 연산 코드(Opcode)와 피연산자인 오퍼랜드(Operand)로 구성됩니다.
연산코드 CPU에서 수행되는 연산 기능입니다.
오퍼랜드 연산에 사용할 데이터 또는 데이터가 저장된 위치 정보입니다.
[어셈블리어 명령어인 push rbp에서 push는 연산 코드이며, rbp는 오퍼랜드에 해당]
연산 코드의 주요 유형
연산 코드는 기능에 따라 크게 네 가지로 분류합니다.
- 데이터 전송: move, store, load, push, pop
- 산술/논리 연산: add, subtract, multiply, divide, increment, decrement, and, or, not, compare
- 제어 흐름 변경: call, return, jump, conditional jump
- 입출력 제어: read, write

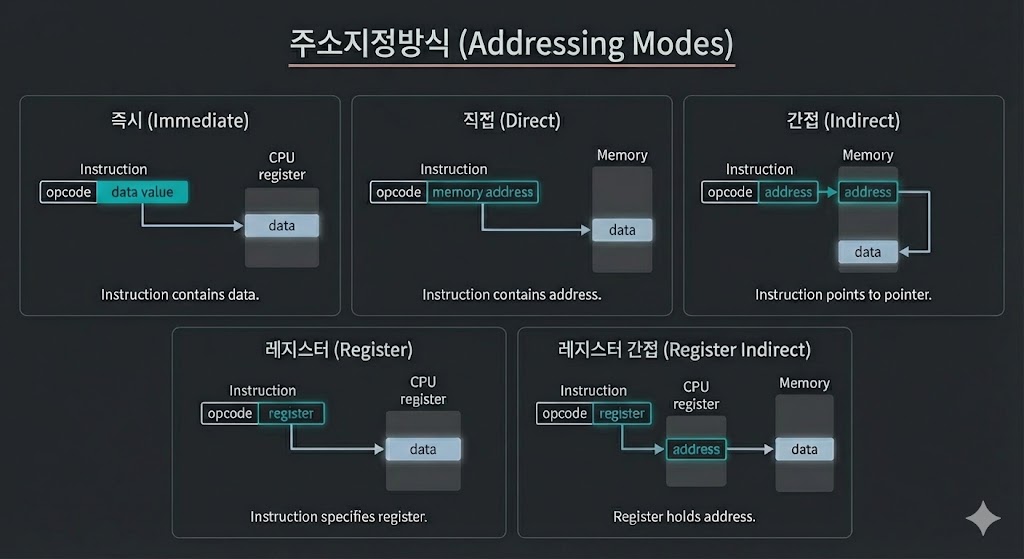
주소 지정 방식
오퍼랜드 필드에 담긴 정보를 이용해 유효 주소를 결정하는 방법입니다.
[제한된 명령어 비트로 메모리에 접근하는 방식들]
Immediate Addressing(즉시)
- 연산에 사용할 데이터를 즉시 명시합니다.
[메모리나 레지스터를 찾을 필요가 없어 속도가장 빠르지만, 표현 데이터 크기가 제한]
Direct Addressing(직접)
- 데이터가 저장된 메모리의 유효 주소를 직접 가리킵니다.
[유효 주소를 표현하는 필드 크기가 연산 코드만큼 줄어 표현 가능한 주소 범위가 좁음]
Indirect Addressing(간접)
- 유효 주소가 저장된 메모리의 주소(간접적)를 기입합니다.
[메모리 접근이 두 번 이상 발생해 속도가 상대적으로 느림]
Register Addressing(레지스터)
- 연산에 사용할 데이터가 CPU 내부 레지스터에 저장된 방식입니다.
[CPU 내부 자원을 이용하여 직접 주소 지정 방식보다 처리가 빠름]
Register Indirect Addressing(레지스터 간접)
- 데이터의 유효 주소를 CPU 내부 레지스터에 저장한 방식입니다.
[레지스터에 유효주소가 있어 메모리 접근 횟수가 간접 주소 지정 방식보다 적음]
번외
스택과 큐
Stack은 후입선출(LIFO) 구조입니다.
데이터 관리를 위해 Push와 Pop 연산을 사용합니다.
Queue는 선입선출(FIFO) 구조입니다.
먼저 들어간 데이터가 먼저 나오는 순서를 따릅니다.
Leave a comment